
Статьи о CAD/CAM и ЧПУ
Обнаружение аномалий ЧПУ с помощью машинного обучения без учителя (Часть 4)
- Лу Чжан (Lou Zhang); Перевод: Андрей Ловыгин
ПРЕДВАРИТЕЛЬНЫЕ ПРИМЕРЫ


Источник:
https://www.machinemetrics.com/techblog/detecting-cnc-anomalies-with-unsupervised-learning-part-4 Мы определили пять различных категорий аномалий:
- Аномалия предшествует отказу станка/тревоге
- Аномалия возникает одновременно с тревогой
- Аномалия предупреждает нас о внутренних ошибках
- Аномалия возникает, когда происходит что-то интересное, но не катастрофическое
- Шумовые аномалии
Пример 1: предшествуя ошибке инструмента
Первоначальная цель такого подхода состоит в том, что мы предположили, что станки испытывают аномальное поведение непосредственно перед отказом. Мы записали несколько случаев - здесь мы кратко опишем пример одного из случаев.
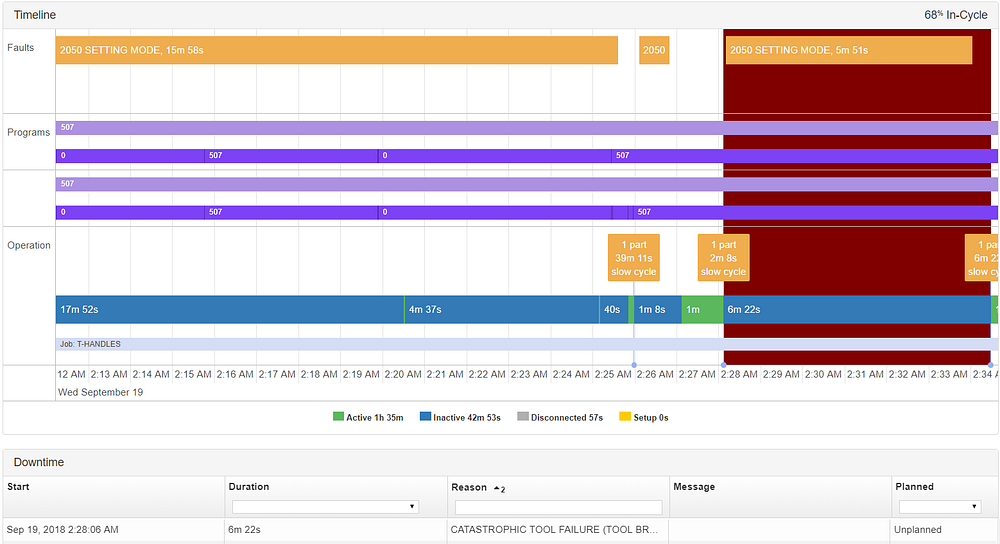
Аномалия была поймана в 2:25 (ночью), а спустя 3 минуты в 2:28 произошла катастрофическая поломка инструмента.
Деталь, созданная в 2:25, была аномальной, за две детали до того, как станок сломал инструмент
Если мы пойдем немного глубже, чтобы увидеть, что же такого особенного в этой детали, мы можем легко визуализировать, что произошло. Давайте вернемся назад от кластеризации к сигнатурам деталей, чтобы диагностировать эту проблему.
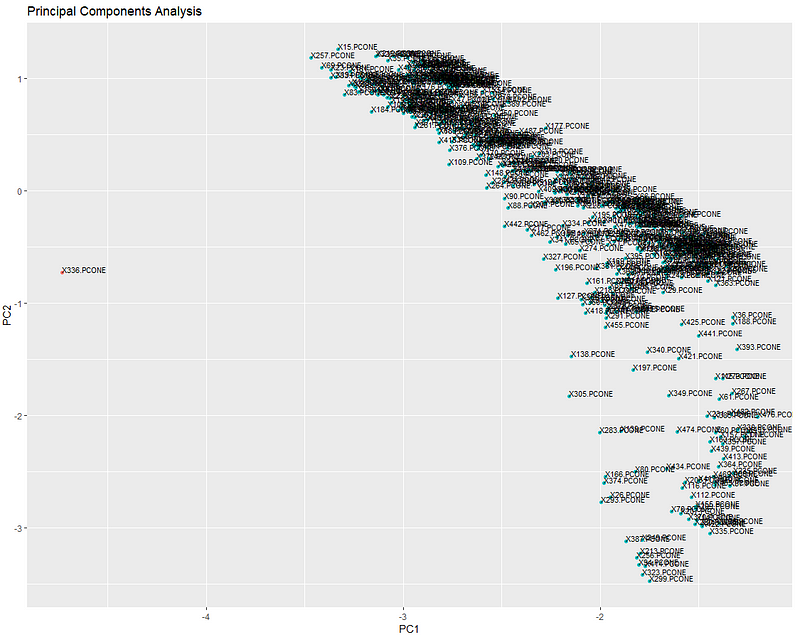
Уровень кластеризации
Я наблюдаю аномалию …
С 22 до 6 часов было изготовлено около 450 деталей. На графике выше показано относительное положение сигнатур деталей при проецировании на 2D-плоскость. Как мы видим, на уровне кластеризации, здесь явно наблюдается аномалия. Все остальные детали сгруппированы вместе, и DBSCAN легко изолирует аномалию, плавая там в одиночестве в космосе. Давайте переместимся на один уровень глубже.
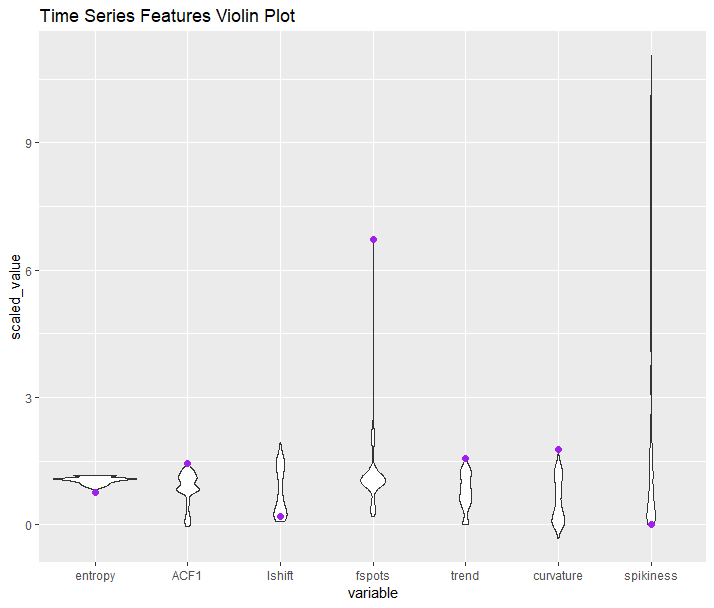
Уровень временных рядов
Приведенный выше кластерный график создается из признаков временных рядов, которые извлекаются из каждой сигнатуры детали. Давайте посмотрим, где особенности аномалии падают относительно всех других деталей (выделены фиолетовым цветом).
Мы можем видеть, что все характеристики нашей аномальной детали находятся на крайнем уровне для этих метрик, что объясняет, почему это так далеко от всего остального. Копаем на один уровень глубже …
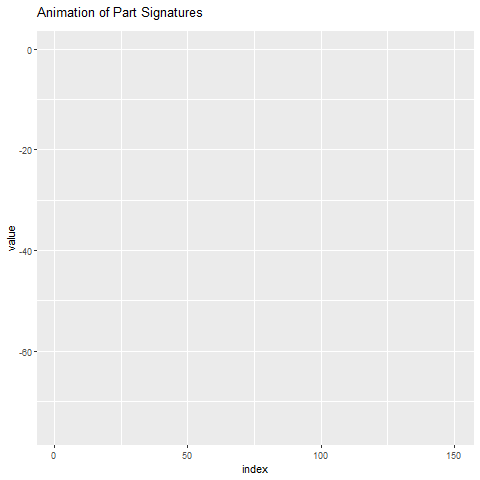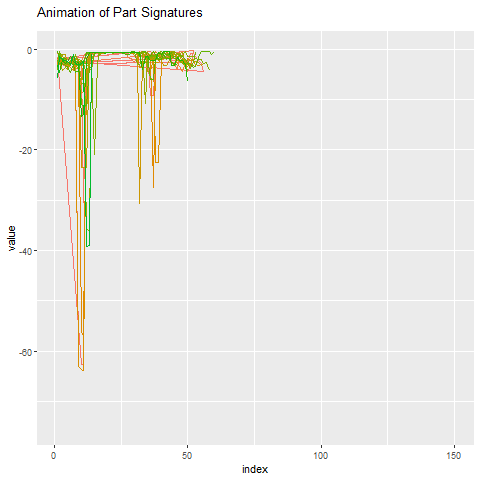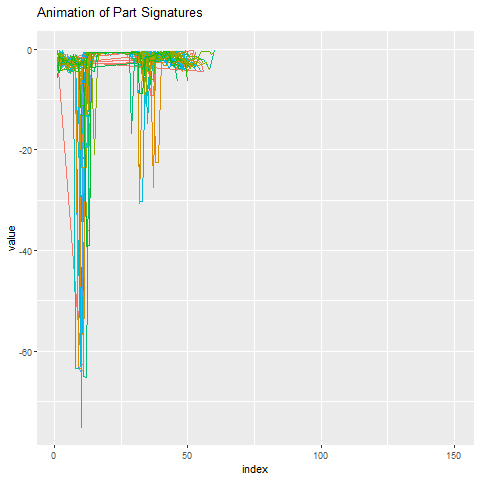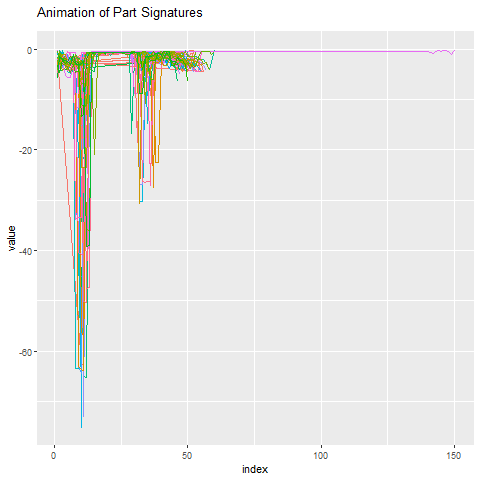
Уровень сигнатуры детали
Как выглядит эта сигнатура детали по сравнению со всем остальным? Ниже мы анимируем 50 сигнатур деталей вокруг аномальной детали. Еще раз, довольно очевидно, какой из них является выбросом.
Создание сигнатуры детали ускорено в 100 раз по сравнению с реальной производственной средой
Последствия прогнозирования отказов инструмента очень значимы. С одной стороны, время простоя и затраты сводятся к минимуму благодаря экономии средств на затратах оператора и замене инструментов. Также может быть полезно знать, что на вашем производственном предприятии есть алгоритм, который ищет проблемные области.
Пример 2: Обнаружение отсутствия СОЖ
На этом станке в 9:39 была обнаружена аномалия, и сразу же последовала тревога «нет СОЖ». Операторы были бы уведомлены непосредственно перед тем, как в станке закончилась охлаждающая жидкость.
13 августа, 9:39. Охлаждающая жидкость кончается. Станок перестает работать
Кто-то может спросить – какой в этом смысл, если я все равно получу сигнал тревоги через пару секунд?
Дополнительным преимуществом здесь является то, что операторы не всегда внимательны к сигналам тревоги, часто обращая внимание на уведомления только после длительного периода простоя. Вместо того чтобы дать станку поработать на холостом ходу до тех пор, пока он не получит предупреждение, оператор может сократить общее время простоя станка, реагируя на текст аномалии.
Станок залит охлаждающей жидкостью. Охлаждающая жидкость имеет важное значение
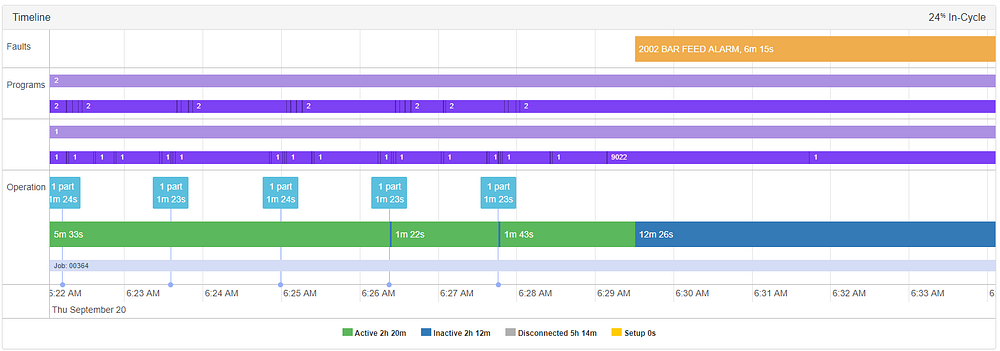
Пример 3: предшествующие сигналы тревоги податчика прутка
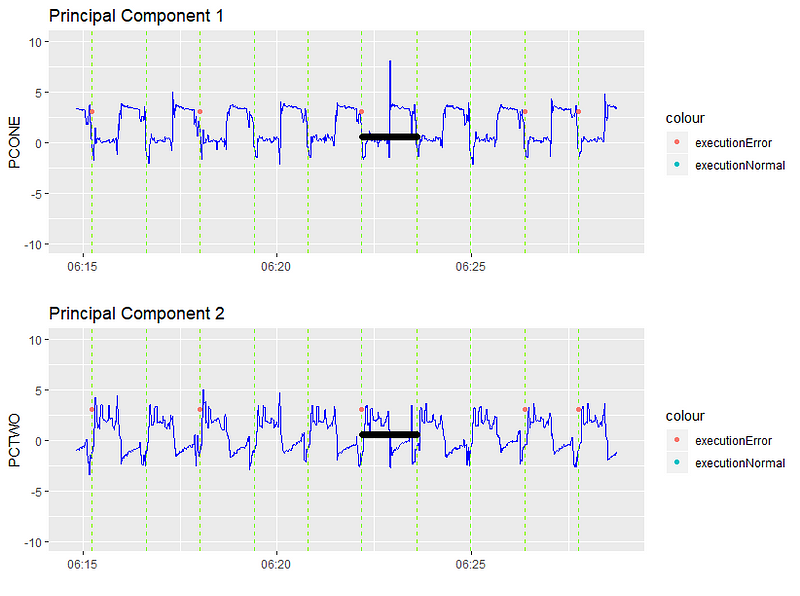
В последнем примере этой категории оператор получил предупреждение примерно за 6 минут до «ОШИБКА ПОДАТЧИКА ПРУТКА», в 6:23.35. Давайте посмотрим на это на временном графике.
Погрузившись в пространство основных компонентов, давайте посмотрим, как это выглядит.
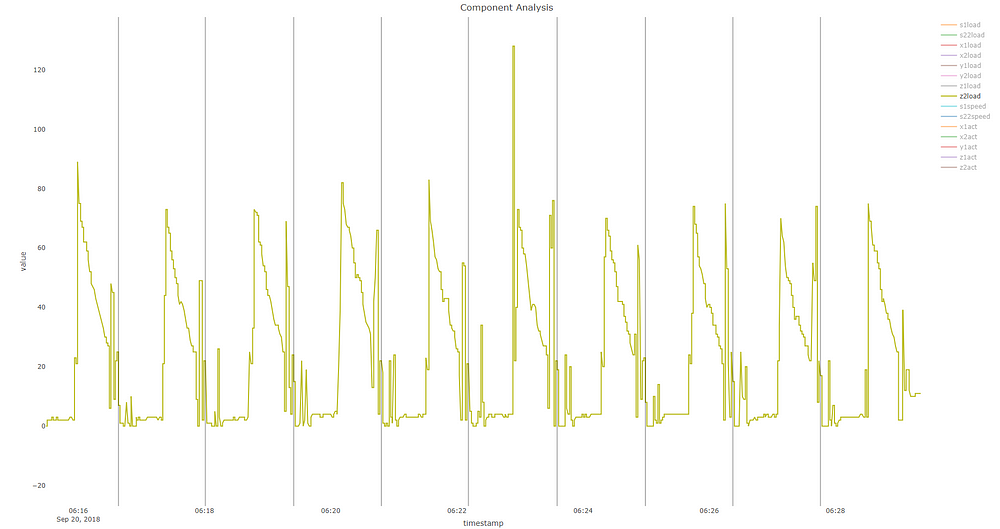
Аномалия выделена черным. Мы можем ясно увидеть всплеск в первой главной компоненте. Давайте еще глубже погрузимся в сами сигналы, чтобы увидеть, что произошло.
Если посмотреть только на нагрузку Z2, то, по-видимому, в 6:22.56 произошло что-то странное, о чем свидетельствует скачок нагрузки с пика 80 на деталь до более 120. В дополнение к этому, паттерны волны вокруг этого времени также отличаются - вы можете увидеть явные несоответствия с другими сигналами вокруг этой области. Конечно, из-за природы PCA, вероятно, что другие сигналы, не показанные на этом графике, также внесли свой вклад способами, не очевидными для невооруженного глаза.
Категория 2: Аномалия возникает одновременно с тревогой
Неудивительно, что мы также обнаружили аномалии, вызванные одновременно с тревогой. Аварийные сигналы встроены производителем, чтобы предупредить операторов о чем-то необычном (как и наши оповещения об аномалиях, поэтому неудивительно, что они часто совпадают). Это может быть выгодно, так как, как уже упоминалось, клиенты не всегда обращают внимание на сигналы тревоги. Аварийный сигнал + аномалия может заслуживать большего внимания, особенно если каждый день появляются десятки ложных сигналов тревоги.
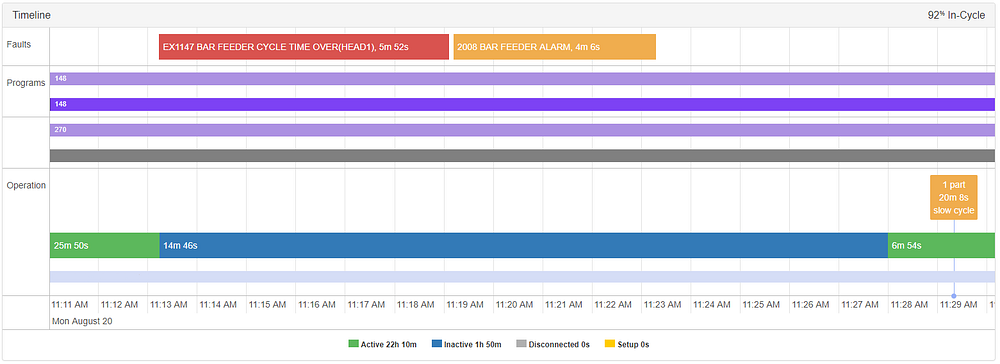
Эти пары тревога-аномалия, которые указывают на то, что станок работает совершенно по-другому, также могут быть более серьезными, чем процедурные тревоги. В приведенном ниже примере аномалия была обнаружена в 11:29, и совпала с тревогой «время цикла податчика прутка истекло», которая начинается, когда для барфидера заканчивается материал.
Аномалия предупреждает нас о сбое в установке, который произошел с обрабатываемой деталью. Деталь, возможно, так или иначе была смещена из положения
Категория 3: Аномалия предупреждает нас о внутренних ошибках
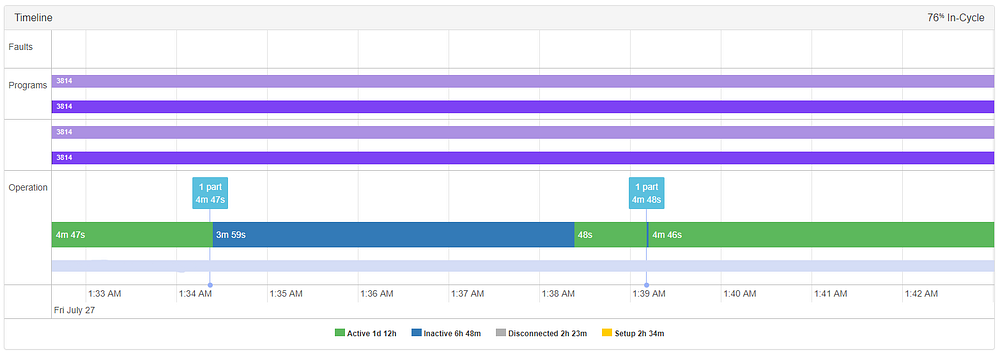
В качестве бонусного побочного эффекта мы также обнаружили пару внутренних ошибок, которые проявились как аномалии на наших станках. В приведенном ниже примере мы обнаружили странный случай, когда станок фактически был активным, хотя технически он был помечена как «неактивный». Это заставило станок записать аномалию для детали, созданной в 1:39.
Это произошло потому, что мы считываем данные в обнаружение аномалий только когда станок активен, и мы инициировали аномалию, увидев усеченную сигнатуру детали. После подтверждения того, что станок действительно был активен в нашем потоке необработанных данных, мы смогли быстро выявить и устранить ошибку, заключающуюся в том, что наш конвейер данных время от времени отбрасывал наблюдения.
Станок был отмечен как неактивный в течение 3 мин 59 сек, когда он был на самом деле производил обработку
Категория 4: Аномалия предупреждает операторов, когда происходит необычная деятельность (но не катастрофический отказ)
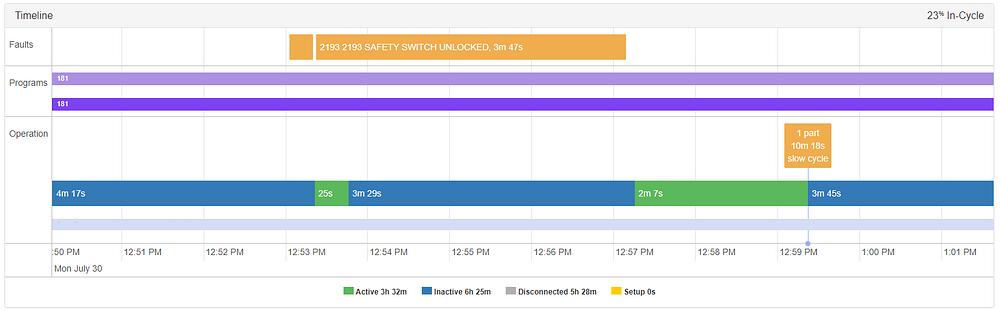
Не всем сбоям инструмента предшествуют аномалии, и не все аномалии совпадают или предшествуют сбоям инструмента. В этом случае срабатывает аварийный сигнал «разблокировка выключателя безопасности», потому что у оператора не было полностью закрытой двери до запуска станка, с сопровождающей его аномалией в 12:59. Станок оставался неактивным, пока это происходило в качестве автоматической меры предосторожности. Хотя это и не является препятствием для работы, мастер участка может захотеть узнать, когда это происходит (особенно, если это повторяется), чтобы поощрять более эффективные методы обеспечения безопасности.
Оператор попытался запустить станок с открытой дверью, вызвав аномалию в 12:59
Категория 5: Аномалия запускается из-за странного поведения, которое не подвергает станок опасности
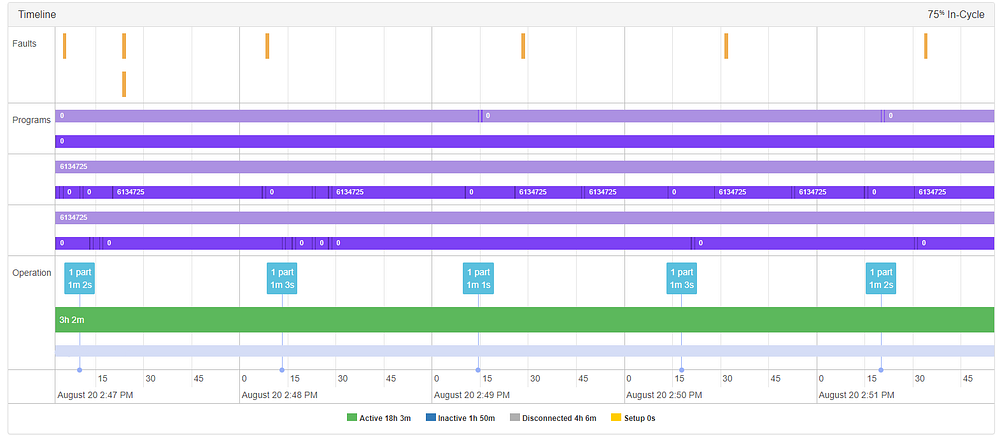
Как всегда, есть крайние случаи, которые не попадают в рамки того, для чего мы разработали нашу систему. В приведенном ниже примере аномалия была вызвана в 2:49, по-видимому, без причины.
Здесь, похоже, нет ничего плохого …
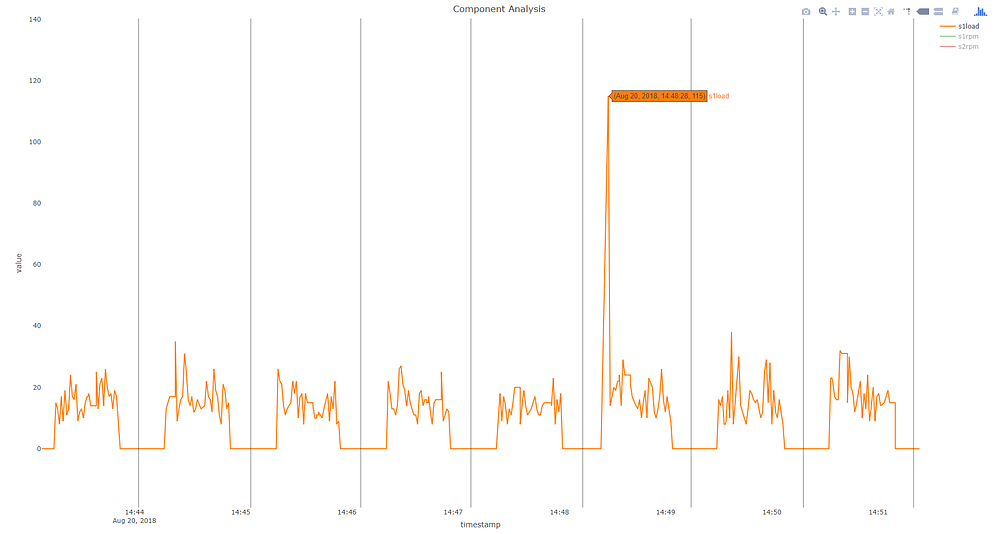
Однако при более глубоком исследовании мы видим, что во время цикла обработки детали наблюдается скачок нагрузки s1 (нагрузка на шпиндель 1). Этого всплеска, который указывал на то, что станок работал при 115% номинальной нагрузки, было достаточно, чтобы вызвать существенную разницу на уровне сигнатуры детали. В данном случае, все было в пределах нормальных рабочих границ этого станка, не вызывая вреда или ошибки.
Пик нагрузки в 14:48.28
Собирая валидирующие данные от наших клиентов, мы можем настроить наши алгоритмы так, чтобы они были более чувствительными к «полезным» аномалиям и менее чувствительными к лишним. Обратная связь должна начать точно определять, какие из атрибутов временного ряда указывают нам на более интересные аномалии. Мы также можем проводить A/B-тестирование, выпуская различные версии алгоритма для определенных клиентов, чтобы узнать, получим ли мы более благоприятную обратную связь. Со временем незначительные улучшения могут привести к значительному повышению точности.
Как Waze, но для станков с ЧПУ
В будущем мы планируем объединить машинное обучение с фильтром аномалий, основанным на знаниях предметной области, чтобы исключить ситуации, которые, по нашему мнению, не интересны. Мы опубликуем эпилог с этим и еще несколькими примерами отказа инструмента в ближайшем будущем.
Продуктизация – Этап пилота
Для нашего пилота мы решили просто докернизировать R-скрипты, которые мы использовали для очистки данных и кластеризации. Эти скрипты выполняют всю тяжелую работу, описанную в частях 2 и 3 этого блога, и нам нужно было только обернуть их в контейнер и внести некоторые изменения в автоматизацию, чтобы они были полностью функциональными в производстве.
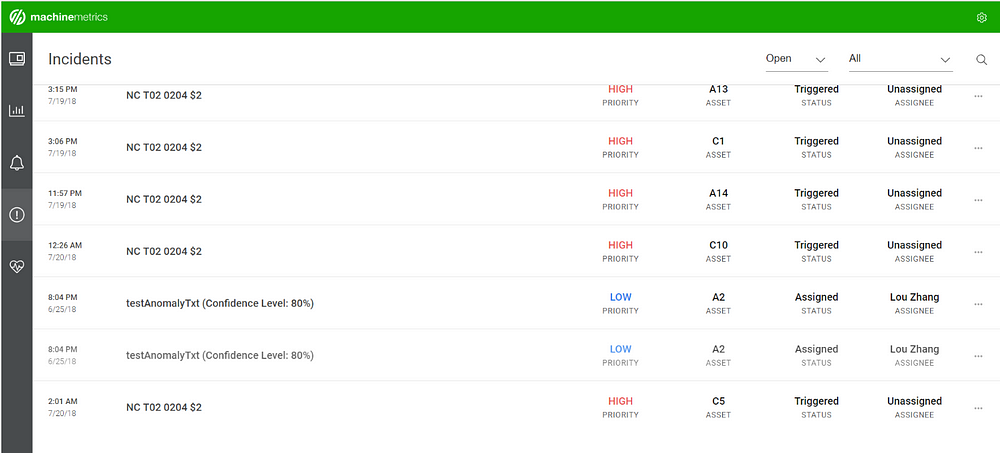
Программа оглядывается назад и запрашивает данные за последние шесть часов, обнаруживая циклы деталей и устанавливая грубую область нормального поведения. После того, как отдельные циклы определены, мы постоянно запрашиваем данные и выявляем аномалии в режиме реального времени. После обнаружения аномалии, аномальная часть записывается и SMS отправляется оператору, в дополнение к генерации инцидента на странице клиента.
Пример инцидента с аномалией, в котором указаны время, приоритет, достоверность и адресат. Клиенты могут определять приоритеты и адресатов, в то время как мы определяем уровень достоверности, основываясь на том, насколько далеко находится отклонение. Другие инциденты на этой странице инициируются определенной пользователем системой, основанной на правилах
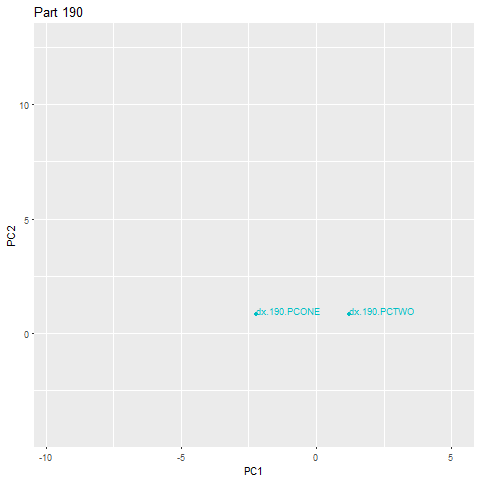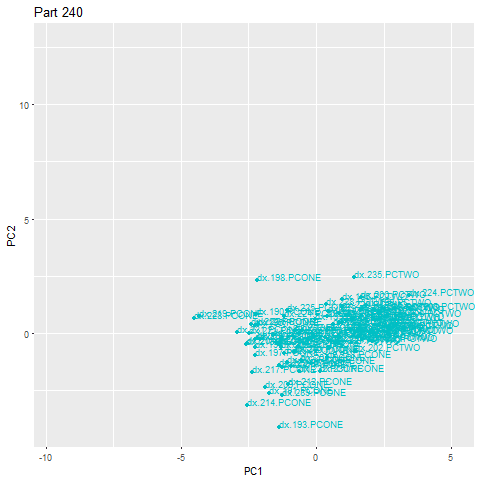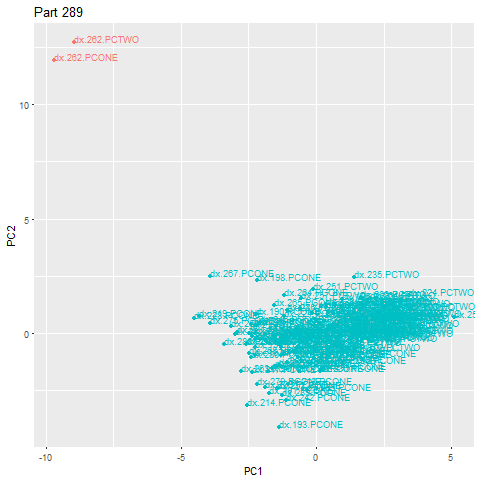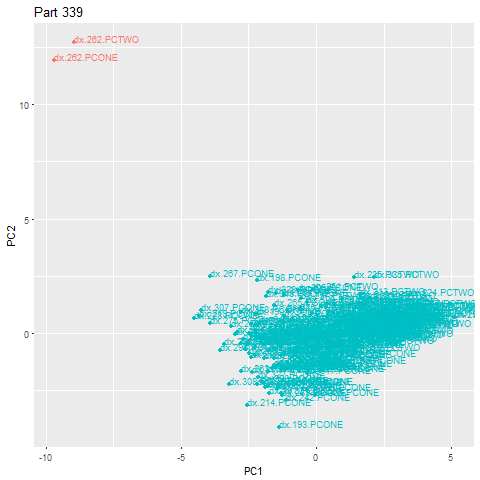
Алгоритм также имеет возможность определять, когда запускается новый тип детали, поскольку мы собираем поле «program_code», которое указывает, какая программа выполняется. Переключение программы очистит облако аномалий и полностью перезапустит процесс.
В приведенном ниже примере деталь 262 является аномалией, выпадающей далеко за пределы основного облака. При обнаружении выброса немедленно запускается оповещение.
Визуализация того, что происходит во время обнаружения аномалий
Мы обернули все это в другой скрипт, который извлекает идентификаторы станков из нашей базы данных и объединяет их в небольшие группы из 15–20 станков. Каждая группа проходит через свои 15–20 станков последовательно и применяет весь процесс к каждому станку. Это вносит некоторую задержку в получение уведомлений получателями, но все же позволяет нам полностью регистрировать и диагностировать аномалии для дальнейшей настройки (что в конечном итоге является целью нашего пилота).
Мы запускаем все это с помощью bash-скрипта, который принимает аргументы, которые изменяют параметры обнаружения аномалий. Это особенно полезно на экспериментальных этапах, поскольку настройку гиперпараметров в основном необходимо выполнять в реальных условиях. Мы имеем дело с уникальной проблемой, потому что трудно проверить аномалии с помощью исторических данных - клиенты часто не помнят, когда станок выходил из строя или испытывал странное поведение. У нас было несколько примеров, которые могли бы помочь нам в этом, но мы не собирали информацию о массовом отказе инструмента в прошлом.
Мы знаем, когда возникают аварийные сообщения на станках, и можем соотнести их с нашими аномалиями. Производители оборудования и клиенты определяют эти аварийные сигналы, которые возникают, когда станок выходит из строя, по соображениям безопасности или когда необходимо выдать предупреждение. Однако трудно распутать ситуацию, когда аварийные сигналы фактически приводят к простою из-за отсутствия стандартизации.
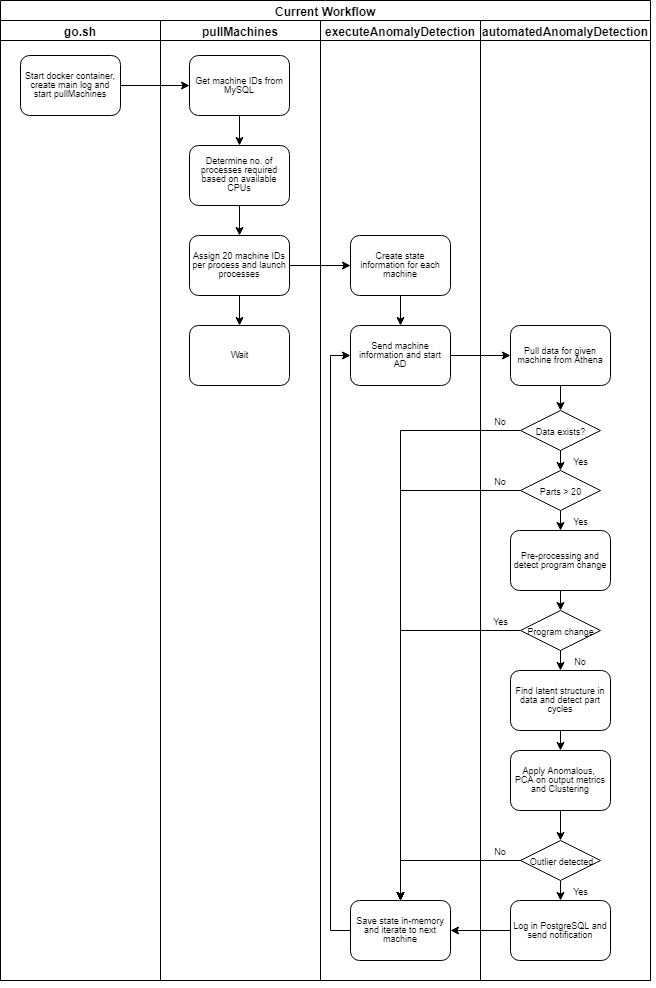
Для справки ниже приведена полная схема для тех, кто интересуется техническими подробностями (или, если вам действительно нравятся блок-схемы).
Следует отметить, что на фронт-энде мы разработали пользовательский интерфейс, позволяющий клиентам отмечать каждую аномалию как «аномальную и полезную», «аномальную и бесполезную» или «не аномалию» для сбора валидирующих данных и для дальнейшего совершенствования наших методов.
Продуктизация – AWS Лямбда
По мере развития процесса наш план состоит в том, чтобы максимально снизить расходы при одновременном повышении надежности. Мы планируем заменить докеризованные R-скрипты функцией AWS Lambda, которая принимает данные непосредственно из нашего потока данных и выполняет всю их обработку. Там не будет необходимости оплачивать расходы на запрос или EC2; обработка будет быстрее, и будет меньше частей, которые могут потерпеть неудачу. Это также позволило бы нам развернуть это локально для объектов, которые не хотят отправлять свои данные в облако.
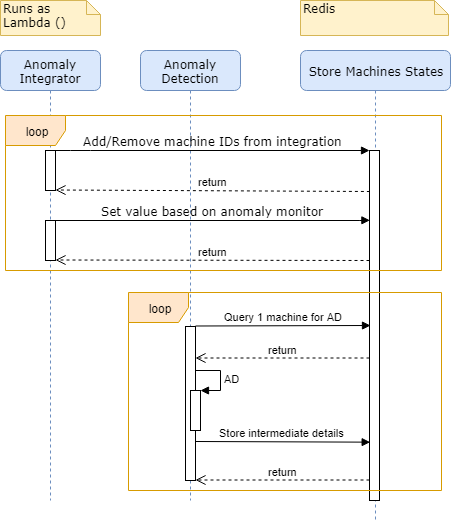
Мы также добавили возможность сохранять информацию о состоянии станков и машинах, на которых мы хотим это запускать, в Redis.
Будет создан парк лямбд, причем каждая лямбда будет обнаруживать аномалии для небольшой группы станков. Как только лямбда завершает обработку микропартии, она сохраняет информацию о состоянии станка. После возобновления она может немедленно получить сведения о станках, на которые была назначена.
Благодарим вас за чтение нашей серии публикаций по обнаружению аномалий. Чтобы узнать больше о MachineMetrics, вы можете посетить сайт.
Читайте также:
- Новое видение мониторинга оборудования и контроля производственного процесса.
- Будущее рынка и технологий CAM. Роль ИИ.
- Обнаружение аномалий ЧПУ с помощью машинного обучения без учителя (Часть 3)
- Как HAAS облегчает жизнь оператору станка
- Новый многоинструментальный станок объединяет 3D-принтер со станком с ЧПУ
- Mazak строит в Японии завод, готовый к технологиям интернета вещей
- Как технология распознавания голоса перевернет машиностроение
- Отличные программы для роботов
- Обнаружение аномалий ЧПУ с помощью машинного обучения без учителя (Часть 1)
- Искусственный интеллект или хайп для станков
Комментарии (0)
Оставьте комментарий
Авторизуйтесь или Зарегистрируйтесь, чтобы оставить комментарий.