
Статьи о CAD/CAM и ЧПУ
Обнаружение аномалий ЧПУ с помощью машинного обучения без учителя (Часть 3)
- Лу Чжан (Lou Zhang); Перевод: Андрей Ловыгин
Выделение сигнатур деталей и создание трансформаций
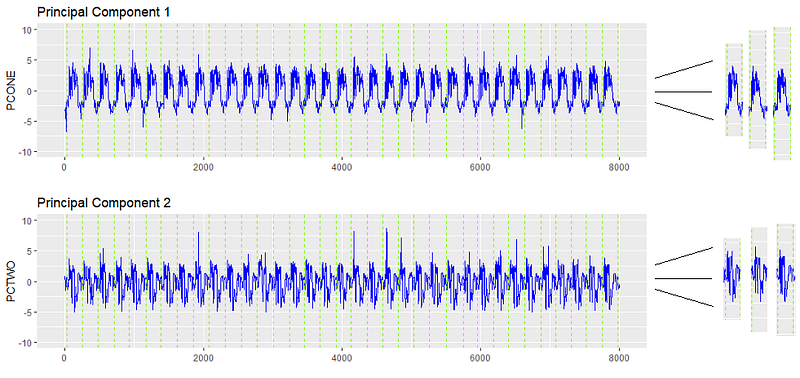
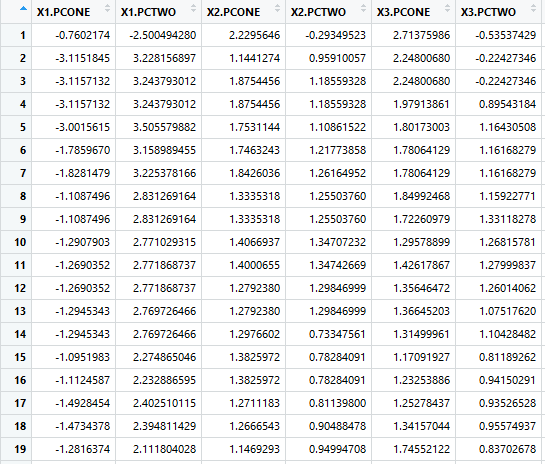
Каждая сигнатура детали теперь представлена этими семью измерениями. На основе этих атрибутов обнаруживаются аномалии, которые сводятся ко всему временному ряду. Результирующая таблица выглядит следующим образом, каждая сигнатура разбита на эти характеристики. Каждая сигнатура детали — это одна строка.
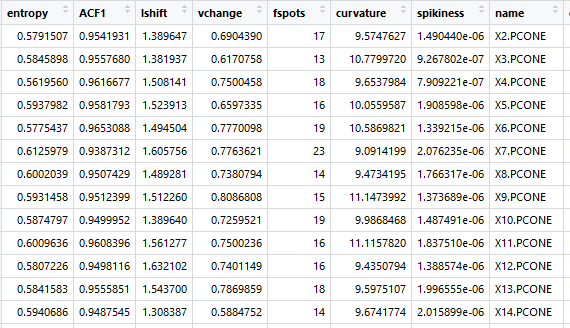

Источник:
https://www.machinemetrics.com/techblog/detecting-cnc-anomalies-with-unsupervised-learning-part-3 Как только мы получим чистый сигнал, нам нужно разделить этот сигнал на отдельные компоненты, сигнатуру обработки детали. Каждая сигнатура обработки детали представляет одну изготавливаемую деталь и соответствующие позиции, подачи, скорости и нагрузки, которые с ней ассоциированы.
Мы берем каждую сигнатуру и выстраиваем их рядом друг с другом, создавая таблицу, в которой каждая «переменная» представляет собой уникальную создаваемую деталь и связанные с ней данные.
Определение скрытой структуры сигнатур деталей
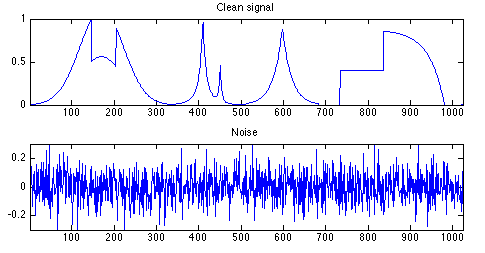
Для нашего следующего шага мы обратимся к Робу Хиндману и его anomalous пакету, чтобы обнаружить скрытую структуру каждой переменной. Причиной этого является то, что исходные значения каждой сигнатуры слишком волатильны, чтобы сравнивать их друг с другом, даже когда они сглаживаются путем взятия скользящих средних или других преобразований. Таким образом, мы должны найти другой способ представления этих сигнатур более стабильным образом. Хиндман определил несколько ключевых метрик временных рядов, которые отражают их присущие качества. Мы выбираем наиболее подходящие для этого варианта использования, которые описаны ниже в нетехнических терминах. Они используются для количественной оценки внутренних факторов каждой части сигнатуры.
- Энтропия: измеряет уровень белого шума в ваших рядах.
- Автокорреляция первого порядка. Автокорреляция первого порядка — это показатель корреляции последовательных элементов во временных рядах. С точки зрения непрофессионала, он измеряет, насколько предсказуем ряд, если вы знаете предыдущий элемент ряда. Это актуально, потому что аномальные ряды часто отображают функции автокорреляции, отличные от неаномальных рядов. По сути, это еще одна мера случайности в ряду, которая часто бывает чрезвычайно высокой или низкой для аномальных рядов (может быть очень низкой, если станок ведет себя хаотично, или очень высокой, если есть необычное повторение или предсказуемость).
- Сдвиг уровня: Максимальное изменение средних значений в ряду при заданном окне. Хорошо подходит для обнаружения аномалий, когда станок испытывает внезапное изменение показателей. Подумайте, когда метрики внезапно перепрыгивают с одного уровня на другой.
- Изменение дисперсии: максимальное изменение дисперсии в серии. Хорошо подходит для обнаружения аномалий, когда станок испытывает внезапное изменение дисперсии. Подумайте о том, когда море внезапно становится спокойным после шторма, или когда станок становится необычайно тихим.
- Кривизна: сообщает, насколько «изогнута» сигнатура детали. Значение — это коэффициент многочлена второго порядка (x²) при подгонке к ряду. Это актуально, потому что циклы деталей имеют искривление из-за циклического характера механической обработки, а значение кривизны одинаково среди неаномальных кривых.
- Остроконечность: дисперсия остатков при подгонке к линейной кривой. Называется «остроконечность», потому что ряды, которые имеют больше пиков, имеют более высокую дисперсию остатков.
- Плоские точки: количество плоских точек в ряду с использованием дискретизации. Хорошо подходит для определения, когда станок глохнет или зависает.
Проецирование скрытых элементов на 2D-плоскость с использованием PCA
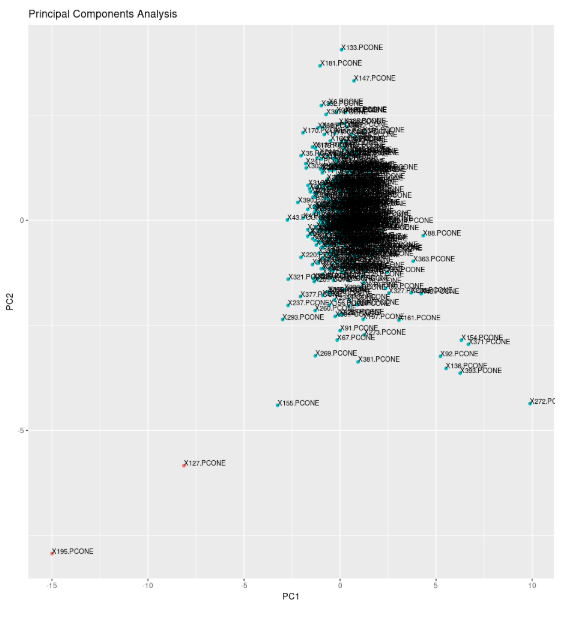
Как только мы получим эти метрики, мы применим PCA к этим семи измерениям, чтобы свести их к двум главным компонентам. Затем мы построим две главные компоненты на двухмерной диаграмме рассеяния.
Глядя на график выше, мы можем видеть, что существует центральный кластер сигнатур деталей, с некоторыми разбросанными сигнатурами на окраинах и в некотором отдалении. Те, которые «далеко» — это наши аномалии. Те, которые немного далеко, могут отражать нашу погрешность измерения или являются незначительными отклонениями от обычной обработки, включающими в себя такие сценарии, как небольшое отклонение нагрузки или скорости шпинделя из-за условий окружающей среды.
Почему мы не использовали преобразования?
Следует отметить, что мы протестировали несколько преобразований наших данных, в том числе логарифметические преобразования, скользящие средние, скользящее стандартное отклонение и первую производную. Мы обнаружили, что использование непреобразованной сигнатуры является наиболее эффективным способом обнаружения аномалий, как наиболее отделенных от других точек в пространстве 2D PCA. Это также имеет смысл теоретически, так как:
- Логарифмическое преобразование ряда выравнивает остроконечности в каждом ряду, что может исключать критическую информацию
- Скользящее среднее делает то же самое и удаляет ключевые признаки, обнаруженные пакетом anomolous
- Скользящее стандартное отклонение может пренебречь важными элементами при усилении атрибутов, связанных с дисперсией, что может быть не тем, что мы хотим
- Первая производная может акцентировать изменения в сигнатуре, которые относительно незначительны, и, таким образом, скрыть истинную природу сигнатур
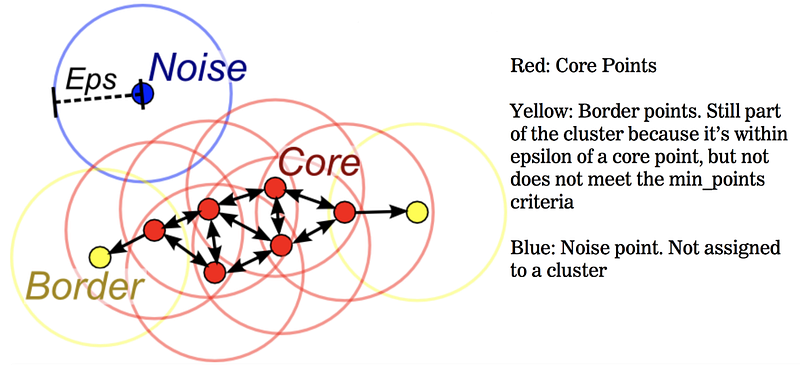
Мы, конечно, можем наблюдать выбросы, но использование кластеризации является стандартизированным способом определения того, когда что-то является выбросом. Мы используем алгоритм DBSCAN, который обнаруживает кластеры, рисуя окружность вокруг каждой точки и ища другие точки в ее окрестности. Для DBSCAN требуются два критических аргумента - «эпсилон», представляющий собой круговую область, нарисованную вокруг каждой точки для определения окрестностей кластера, и «порог минимальных точек», который представляет собой число точек, которые должны находиться в этой окрестности, чтобы его можно было рассмотреть как кластер.
Иллюстрация DBSCAN приведена ниже. «Базовые» точки считаются неаномальными, «граничные» точки, которые находятся на границе круга, также являются неаномальными. Однако «шумовые» точки, которые полностью находятся за пределами центральной области, являются аномалиями.
Определение эпсилона
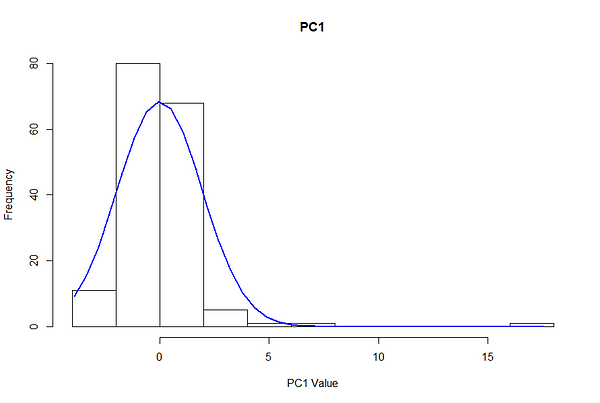
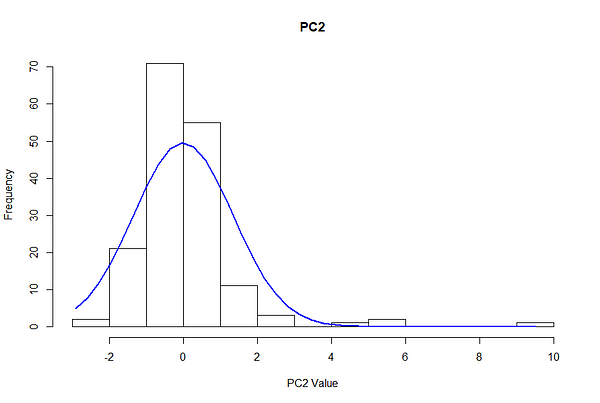
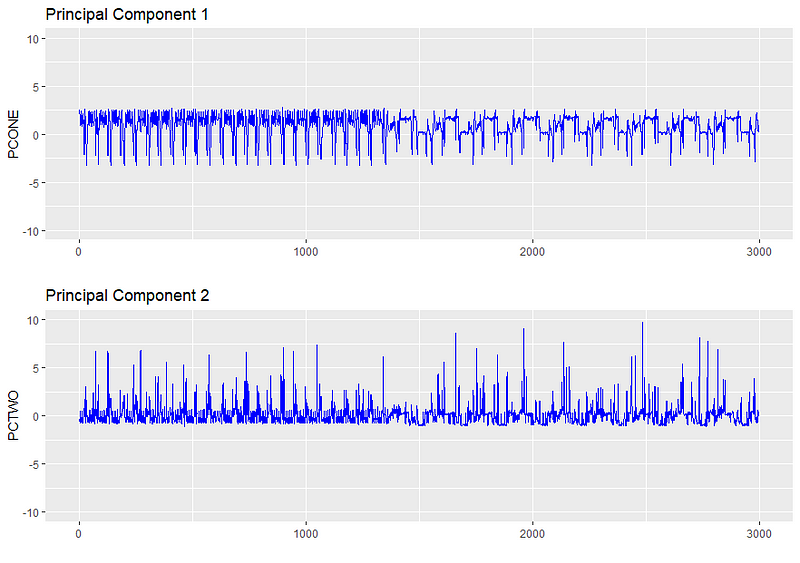
Процесс настройки требовал рассмотрения распределения данных и выбора параметров, которые изолировали небольшую часть точек, но не исключали полностью аномалии. Чтобы получить приблизительный порядок величины эпсилона, мы строим распределения для Главной компоненты 1 и Главной компоненты 2, используя этот конкретный сценарий в качестве примера большинства сценариев.
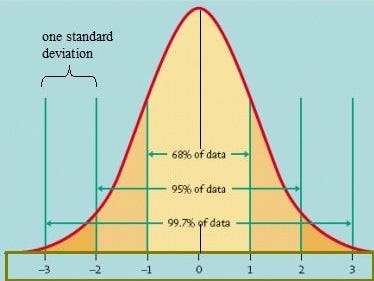
Из-за центрирования главные компоненты примерно нормально распределены со средним нулем и стандартным отклонением 1,5. При нормальном распределении 68% наблюдений охватываются одним стандартным отклонением, 95% - двумя и 99,7% - тремя.
Это означает, что при стандартном отклонении 1,5 PC ~ 68% наблюдений приходится на 1,5–1,5 PC, 95% на значения от -3 до 3, а 99,7% - от -4,5 до 4,5.
Мы знаем, что без учета аномальных станков, средний показатель брака для клиентов MachineMetrics, включая человеческую ошибку, составляет ~ 1/1000 деталей, что составляет 99,9% успеха (заказчики MachineMetrics в совокупности изготовили 327 миллионов деталей, а 224 тыс. были испорчены). Хотя этот показатель может показаться высоким, мы должны помнить, что наши клиенты — это, в основном, небольшие механические цеха, у которых может не быть большой серийности одной и той же детали. Кроме того, большая часть наших клиентов — это специализированные мастерские, которые производят детали на заказ для других компаний, что дает им меньше времени для совершенствования производственного процесса и, таким образом, оставляет больше места для совершения ошибок.
MachineMetrics отслеживает каждую деталь, изготовленную станками, к которым мы подключены, что дает нам доступ к уникальному набору данных для интеллектуального анализа данных
При нормальном распределении 99,9% наблюдений находятся в пределах 3 стандартных отклонений, что в нашем случае составляет ± 4,5 единицы в значениях главных компонент. Принимая во внимание тот факт, что точность (предотвращение ложных срабатываний) более важна, чем отзыв (захват всех аномалий) при первом пилотировании этого метода, мы устанавливаем наш порог эпсилона равным 4 стандартным отклонениям, то есть точки должны падать на 6 единиц от центрального, чтобы называться выбросами/аномалиями. Мы считаем точность более важной, потому что клиенты могут игнорировать уведомления, если их слишком много, и мы хотим избежать ненужной паники*.
*эта часть все еще находится в стадии пилота и параметры могут быть изменены
Определение минимального порогового значения
Порог минимальных точек устанавливает минимальное количество точек, которые должны быть сгруппированы вместе, чтобы его можно было рассматривать как свой собственный независимый кластер, а не просто как точки выброса. Это может быть полезно в обстоятельствах, когда на самом деле имеются не выбросы, а периоды со сменой инструмента или другие системные, но нормальные различия. В этих случаях станок может сбрасываться в нормальное состояние за короткий промежуток времени. Мы определяем этот порог в 10 баллов.
Таким образом, мы определяем кластер, который должен иметь минимум десять точек, а размер радиуса эпсилона равен 6 единицам. Все, что падает за 6 единиц основного облака и имеет менее 10 точек рядом с ним, является аномалией. В этом случае мы обнаружили две аномалии, соответствующие двум деталям, которые имели «посторонние» признаки обработки. Мы можем определить, когда эти детали сделаны, и кодировать время, соответствующее им, как время, когда станок демонстрировал аномальное поведение.
Проверка аномальной детали
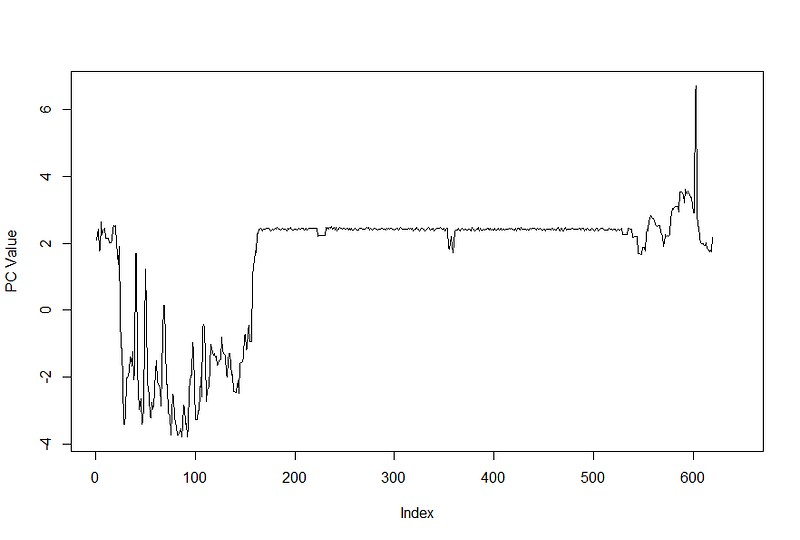
Деталь 127 обнаружена как аномальная, была создана между 3:04 и 3:07 утра. Давайте посмотрим, как выглядит сигнатура.
Как мы видим, в сигнатуре детали была определенная разница. В этом случае станок завис на несколько минут, перезагрузился и продолжил обработку. Хотя на этот раз не было немедленных последствий, оператор был предупрежден об этом и предпринял дальнейшие шаги для расследования неожиданных зависаний, поскольку это может привести к поломке инструмента в будущем.
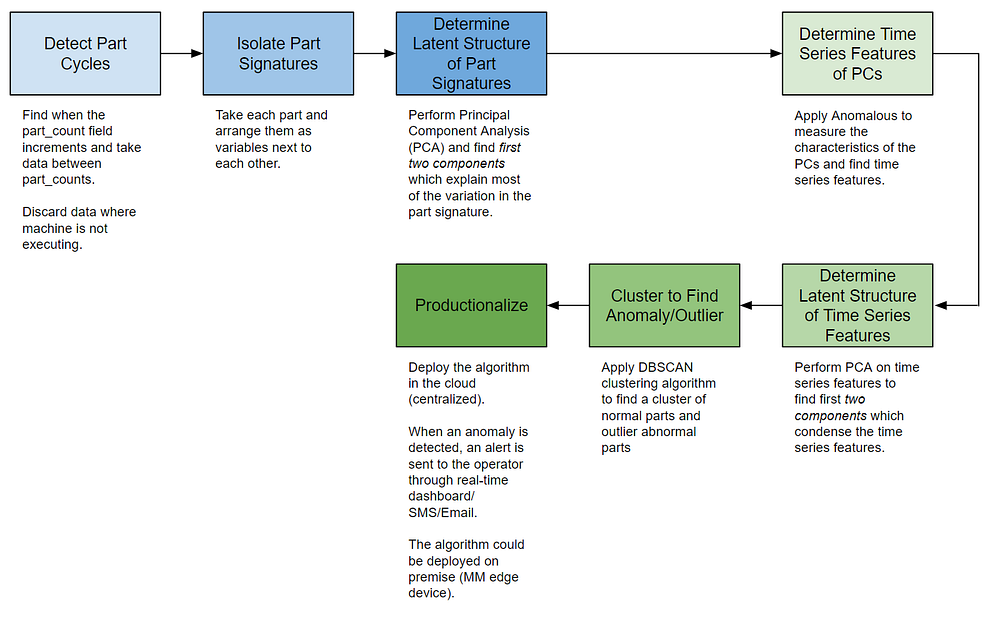
Краткое изложение шагов
Чтобы помочь обобщить все, ниже приведена блок-схема для облегчения понимания процесса. В последней части нашей серии мы рассмотрим продуктизацию.
Альтернативный вариант использования
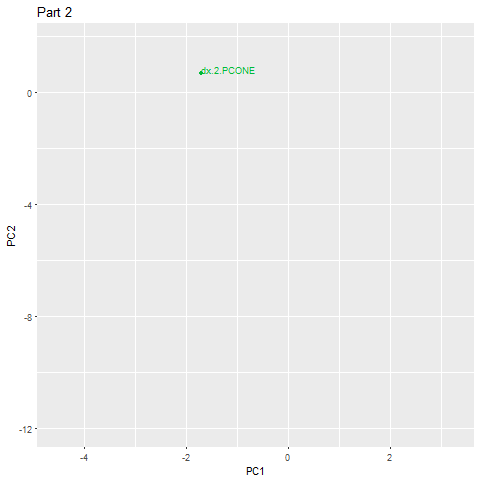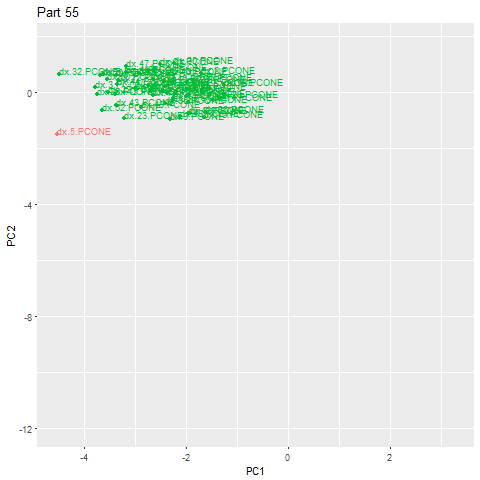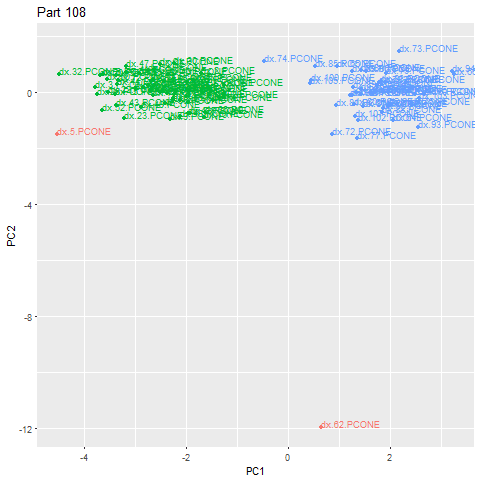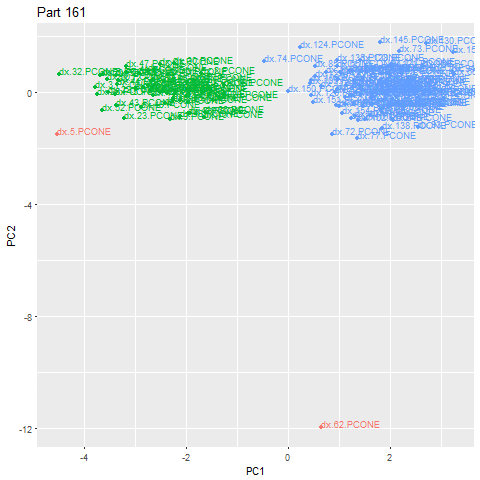
Альтернативное использование этого метода - обнаружение, когда производимая деталь изменилась. Используя те же шаги и настраивая эпсилон, чтобы он был более подходящим для ситуации, мы можем определить, когда сигнатуры деталей выглядят структурно иными и образуют другой кластер. В приведенном ниже примере мы можем видеть, что в 62-й детали произошло изменение детали (эта деталь сама по себе является аномальной из-за фактического процесса замены, но мы можем добавить дополнительные правила, чтобы исключить аномалии). Зеленое облако — это один тип детали, а синее - другое. Это позволяет нам автоматически классифицировать детали, изготовленные клиентом.
GIF был ускорен для эффекта. Детали фактически создаются за цикл ~ 83 секунды
Мы можем оглянуться назад и увидеть, что характеристики сигнатур детали действительно видят существенный сдвиг при изготовлении новой детали.
Зуммирование вида сигнатур деталей в период изменения
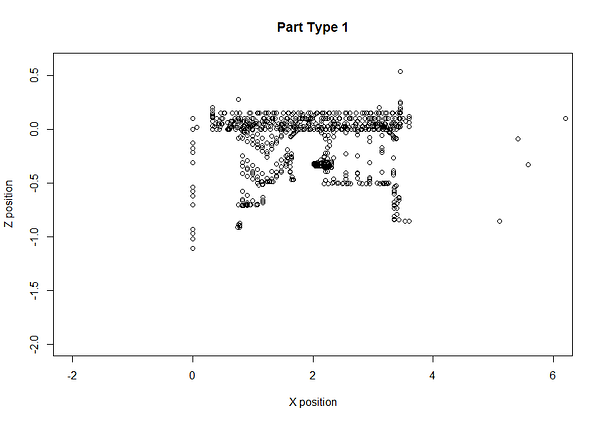
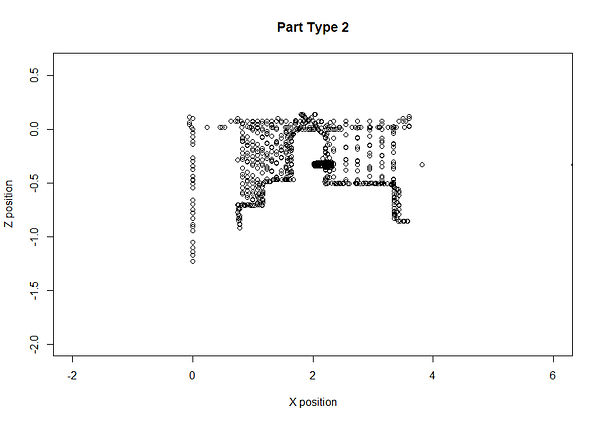
Мы проверили данные на основе достоверности в нашей базе данных и подтвердили, что в это время был изготовлен новый тип детали. Так как MachineMetrics отслеживает и сохраняет позиции инструмента, мы можем даже построить деталь, чтобы убедиться в этом.
Положения инструмента на осях X и Z
Читайте также:
- Обнаружение аномалий ЧПУ с помощью машинного обучения без учителя (Часть 1)
- Отличные программы для роботов
- Обнаружение аномалий ЧПУ с помощью машинного обучения без учителя (Часть 4)
- Блокчейн - инструмент для усовершенствования умного производства
- Как технология распознавания голоса перевернет машиностроение
- Гибрид 5-ти осевого фрезерного станка и 3D принтера, печатающего металлом
- Как HAAS облегчает жизнь оператору станка
- Новое видение мониторинга оборудования и контроля производственного процесса.
- Продукт как услуга в эпоху четвертой промышленной революции
- Искусственный интеллект или хайп для станков
Комментарии (0)
Оставьте комментарий
Авторизуйтесь или Зарегистрируйтесь, чтобы оставить комментарий.