
Статьи о CAD/CAM и ЧПУ
Обнаружение аномалий ЧПУ с помощью машинного обучения без учителя (Часть 2)
- Лу Чжан (Lou Zhang); Перевод: Андрей Ловыгин
Мы пробовали обрабатывать и очищать данные на многих станках, но, чтобы проиллюстрировать наши соображения, выделим только один пример. Начнем с рассмотрения того, как выглядит процесс обработки с нашей точки зрения. Ниже мы построили потоковые данные для подачи, скоростей и нагрузки для одного конкретного станка с 22:00 до 9:00. Это станок делает одну и ту же деталь все время.

Видно, что данные зашумлены - мы не знаем, на что уместно смотреть, и что мы ищем с точки зрения аномалий. Почему сигналы такие нерегулярные и остроконечные, и почему в сигналах есть пробелы? Если станок обрабатывает одну и ту же деталь, то почему наблюдается столь малая регулярность сигналов?
Причина этого – способ, которым MachineMetrics собирает данные. Каждые 900 мс или около того мы открываем «окно» для обнаружения изменений в метриках. Если есть изменение, мы записываем его. Если нет, мы ничего не записываем. Мы делаем это по двум основным причинам:
- Эта частота дискретизации встроена для экономии затрат на хранение данных, обработку данных и пропускную способность. Поскольку мы получаем сотни метрик с каждого из наших станков, экономически не выгодно создавать и поддерживать инфраструктуру для извлечения данных несколько раз в секунду. Это позволяет нам избежать необходимости использовать дорогие сторонние сервисы, например Watson или Azure.
- На старых станках если контроллер опрашивается слишком много раз, то может произойти его замедление или зависание.
Если мы попытаемся применить обнаружение аномалий к этим сигналам без их очистки, обнаруженные аномалии не будут иметь смысла. Мы прогоняем наши временные ряды через пакет anomalize и отображаем результаты ниже. Anomalize выполняет обнаружение аномалий в одном потоке. Аномалии появляются в виде черных точек, которые могут возникать в разное время в различных сигналах.

Хотя некоторые из этих сигналов могут с первого взгляда казаться выбросами, обнаруженные аномалии на самом деле бесполезны. Они не подают знака на действительно необычное поведение, так как больше являются артефактом нашего процесса сбора данных. Итак, пришло время запачкать руки данными. Во-первых, необходимо решить проблему простоя (пробелов). Затем мы перейдем к тому, как сгладить проблему частоты опроса.
Удаление неактивных последовательностей
Неактивные последовательности, смешанные с данными, в большинстве своем означают простой. Этот простой включает время простоя оператора (перекус в 3 часа, новая смена) и время простоя станка (время охлаждения, смены инструмента, и в этом случае две аномалии, которые мы будем декодировать).
Наш первый шаг - выяснить, когда создаются детали и сколько времени требуется для их изготовления. На самом деле нас не волнуют ситуации смены инструмента, когда станок не работал, и мы не хотим, чтобы наш алгоритм воспринимал это как аномалию в процессе обработки.
Наш первый шаг состоит в том, чтобы отличить сигнал (последовательности, которые нас интересуют) от шума (последовательности, которые не имеют значения). Мы также хотим убедиться, что мы не исключаем из данных действительно аномальное поведение.
Чтобы сделать это проще, MachineMetrics собирает значение «part_count» (счетчик деталей), которое увеличивается каждый раз, когда заканчивается цикл обработки детали. Мы считываем это значение, используя два ключевых компонента станка:
- В определенных типах интеграций мы можем подключиться к реле станка и выяснить, какие переключатели увеличивают количество счетчика деталей

- В других типах интеграций мы можем подключиться к программируемому логическому контроллеру (PLC) станка, который содержит сигнал в G-коде (язык программирования ЧПУ), указывающий на завершение обработки детали

Мы хотим сохранить только те наблюдения, где станок активен. На графике ниже красным цветом обозначены области, в которых станок был неактивен (или был в наладке и пр.), и где мы исключили наблюдения.
После очистки сигнал выглядит следующим образом. Обратите внимание на изменение временной шкалы, поскольку удаление наблюдений во временном ряду превращает ее в вектор.

Сигнал теперь выглядит намного аккуратнее, напоминая типичные параметры, такие как вибрация, скорость или мощность. Это важно, потому что методы обнаружения аномалий ранее применялись к этим типам сигналов, и создание аналога этих сигналов расширяет наш набор методологий.
Обнаружение скрытой структуры процесса обработки
По мнению операторов станков критическим фактором, на который следует обратить внимание является взаимосвязь между нагрузками, позициями, скоростями шпинделя и скоростью подачи. Например, не имеет значения, если скорость, подача и нагрузка одновременно падают до нуля — это может просто указывать на то, что станок “отдыхает”. Однако очевидно возникает проблема, если станок продолжает подавать материал, но нагрузки падают до нуля, что указывает на более серьезную проблему. Или, если положение осей продолжается по обычной траектории, но больше нет нагрузки, связанной с этим, что может говорить о поломке инструмента.

Оказывается, несмотря на ошибку измерения окна, отношения в значительной степени остаются одинаковыми для сигнатур нормальной детали из-за количества участвующих наблюдений. Со временем нормальные детали будут иметь аналогичные сигнатуры, хотя диапазон того, как они выглядят, будет больше.
Нам необходимо найти осмысленный способ измерения корреляции или отношения между всеми этими сигналами и разделить их на один или два комбинированных сигнала, охватывающих все подачи, скорости, нагрузки и позиции.
Мы обращаемся к методу, называемому методом главных компонент (principal component analysis, PCA), чтобы разделить наши многочисленные сигналы на два сигнала, которые представляют все из них. PCA берет многомерную матрицу и разделяет ее на «главные компоненты», фиксируя направление наибольшего отклонения. Например, если 70% дисперсии вашего набора данных можно получить в одном измерении, а 95% - в двух измерениях, мы потеряем только 5% информации в наших данных, исключив все другие переменные. Интуитивно понятно, что метод сохраняет комбинации переменных, которые могут наилучшим образом представлять данные, и значение часто может быть получено из этих объединенных переменных как подразумеваемой информации, лежащей в основе вашего набора данных.
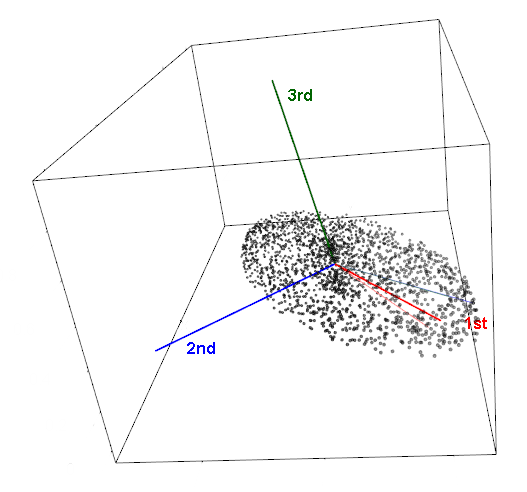
Например, набор данных может иметь четыре переменные - промышленное производство, уровень преступности, индекс потребительских цен и индекс неравенства доходов для каждой страны. PCA может определить, что два основных компонента охватывают почти всю информацию: первый представляет собой комбинацию промышленного производства и индекса потребительских цен, в основном представляющих ВВП (подразумеваемую переменную, лежащую в основе обоих), а второй - комбинацию уровня преступности и неравенства доходов (подразумеваемая переменная, представляющая что-то похожее на социальные волнения).
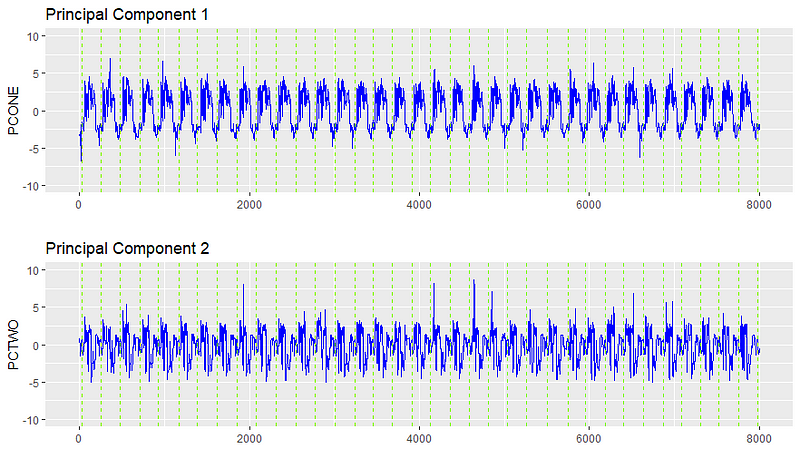
В нашем случае многомерная матрица — это совокупность всех позиций, подач, скоростей и нагрузок (33 переменных для этого станка). Мы сводим все эти переменные к двум главным компонентам, которые собирают важную информацию из 33 исходных переменных. Мы можем идентифицировать разъединения отношений, так как значения в главных сигналах будут чувствительны, когда между оригинальными 33 переменными возникают необычные отношения.

Найдя скрытые сигналы, мы можем построить их и увидеть, что на самом деле есть довольно последовательный сигнал. С этим очищенным сигналом мы можем начать выполнять более трудную задачу по обнаружению аномалий.
Читайте также:
- Как HAAS облегчает жизнь оператору станка
- Отличные программы для роботов
- Будущее рынка и технологий CAM. Роль ИИ.
- Блокчейн - инструмент для усовершенствования умного производства
- Новый многоинструментальный станок объединяет 3D-принтер со станком с ЧПУ
- Новое видение мониторинга оборудования и контроля производственного процесса.
- Искусственный интеллект или хайп для станков
- Обнаружение аномалий ЧПУ с помощью машинного обучения без учителя (Часть 3)
- Гибрид 5-ти осевого фрезерного станка и 3D принтера, печатающего металлом
- Обнаружение аномалий ЧПУ с помощью машинного обучения без учителя (Часть 1)
Комментарии (0)
Оставьте комментарий
Авторизуйтесь или Зарегистрируйтесь, чтобы оставить комментарий.